Content Recommendation E-learning System for Personalized Learners to Enhance User Experience using SCORM

(This article belongs to the Special Issue on Special Issue on Multidisciplinary Sciences and Advanced Technology (SI-MSAT 2025) and the Section Information Systems – Computer Science (ISC))
Export Citations
Cite
Udugahapattuwa, P. and Fernando, S. (2025). Content Recommendation E-learning System for Personalized Learners to Enhance User Experience using SCORM. Journal of Engineering Research and Sciences, 4(9), 30–46. https://doi.org/10.55708/js0409004
Pasindu Udugahapattuwa and Shantha Fernando. "Content Recommendation E-learning System for Personalized Learners to Enhance User Experience using SCORM." Journal of Engineering Research and Sciences 4, no. 9 (September 2025): 30–46. https://doi.org/10.55708/js0409004
P. Udugahapattuwa and S. Fernando, "Content Recommendation E-learning System for Personalized Learners to Enhance User Experience using SCORM," Journal of Engineering Research and Sciences, vol. 4, no. 9, pp. 30–46, Sep. 2025, doi: 10.55708/js0409004.
E-learning is a main field used to improve learners’ learning environment. It would be more useful if the E-learning systems were improved by getting interactions and focusing on user experience. This research suggests increasing the user experience of students towards E-learning environments by recommending content according to their preferences. This research aims to make personalized content recommendations by identifying user interactions, trends, and patterns. Finally, this research provides a model that could help to create an intelligent E-learning system. Then the student engagement towards E-learning and user performance level can be enhanced using this research. After developing the model, there is a 73.99% accuracy in initial training and 63.16% accuracy in initial testing. After retraining and retesting, there was 85.58% accuracy for retraining and 78.90% accuracy for retesting.
1. Introduction
1.1. What is E-learning?
E-learning is a method that is used to provide education. E-learning is the use of the Internet and other digital technologies to facilitate learning outside of the traditional classroom setting. The key components and features of E-learning can be mentioned as content delivery in digitally formats, learning management systems (LMS), online courses and MOOCs, Interactive and Multimedia Tools, Synchronous and Asynchronous Learning, Assessments and Feedback, and Collaborative Learning Tools. The central point of E-learning is learning management systems (LMS). Learners can create, manage, and deliver courses using E-learning because LMSs provide a structured environment. E-learning has some challenges that can be addressed to replace traditional educational methods.
1.2. E-learning Systems
E-learning systems are becoming more common among people which can be used to gravitate toward beyond traditional learning methods. Typically, E-learning systems consist of courses and activities such as quizzes and dis- tribute them among students, post notifications, review assessments, and exams, and accept or reject student enrollment.
1.3. Educational Data Mining
Data mining is used to uncover patterns, correlations, relationships, and anomalies within extensive sets of data to predict future results and trends. Educational data applies to data mining for research needs such as enhancing the educational procedure, leading students to learn, or having a better knowledge of educational phenomena.
Educational Data Mining is a contributing discipline that plays a key role in improving educational outcomes. By mining data types from educational settings and applying data mining techniques, students can gain a deeper under- standing and the environments in which they learn. With the usage of the educational system raised, high amounts of data become available.
Educational Data Mining offers valuable insights into the necessary information and presents a clear profile for learners. Then data mining is used to solve educational-related issues. There are some educational data mining techniques like clustering, prediction, and discovery with models and relationship mining. Then, it can identify novels, interesting, and useful information from educational data.
1.4. Content Recommendation
The content recommendation method can be used to increase user interaction in most E-learning systems. The types of content suitable for different levels should be properly mentioned in a content recommendation system.
1.5. Research Problem
With the increase in popularity in the remote teaching field, more people have a desire to share their knowledge. However, the presentation of knowledge is directly proportional to how efficiently knowledge can be passed on. Everyone has a different capability for learning and the general content delivery system is not very successful. There are some prior research works which are using data mining techniques, can be used to predict performance of students’. Several research works were done on personalized lesson recommendations based on the probabilistic model and agent-based models. However, no significant research has been observed on recommending content based on the subject’s interest from the student in current E-learning systems.
1.6. Research Objectives
This proposed system has two main objectives which are mining data from user interactions identifying user needs and delivering targeted lessons to enhance user interest in relation to lesson content.
- Identify user needs and user interactions through mining data
- To enhance user interest and interaction, develop lessons based on user needs
1.7. Research Questions
Students’ interactions are very crucial to understand user engagement and enhance the learning experience. The students’ interactions can be identified by focusing their activities on the system. Collecting data through surveys and assessments can provide a better understanding of user experiences and preferences. Students’ interactions with the content are required to be evaluated. There are some metrics like the frequency and duration of content access, completion rates of assignments or quizzes, and any interactions or discussions within the system to evaluate. These metrics are useful to enhance the level of student engagement. Personalized learning approaches are necessary to deliver targeted content to increase students’ interactions. Collecting data, such as interactions, performance, preferences, and interests will be useful in creating content for specific needs. Multiple content formats such as texts, audio, or images are useful to engage their preferences and learning styles.
- How to identify student interactions and attractions towards the contents of the E-learning?
- How to evaluate user interest for the E-learning con- tent?
- How to deliver targeted content to each individual student to interact with students?
- How to translate content through different media according to the user’s interests such as when given content is in text format and the targeted audience requires the content in audio format to be interested?
1.8. Research Scope
This project intends to cover the extraction of student behaviors related to interests in the content from E-learning systems of Sri Lanka, developing a simulation of an E-learning system, and testing different content recommendation techniques that can be used to deliver targeted content to the Sri Lankan undergraduate students based on extracted data and user interest levels.
1.9. Research Significance
The proposed research will help to enhance the interest students have in the content through targeted delivery of
content. By analyzing and understanding individual student preferences, learning styles of students, and students’ relationships, the E-learning system can deliver content by aligning with their essential requirements and interests. This personalized method enhances the preferences of students to be motivated and engaged with the relevant materials. Somehow, if one student has shown preference for audio-based content, then the system can provide audio- based text-based content, that can be accessed and appealed to that student. The research targets to provide a more personalized and engaging learning experience by adjusting the material delivery to the interests of the individual.
1.10. Research Outline
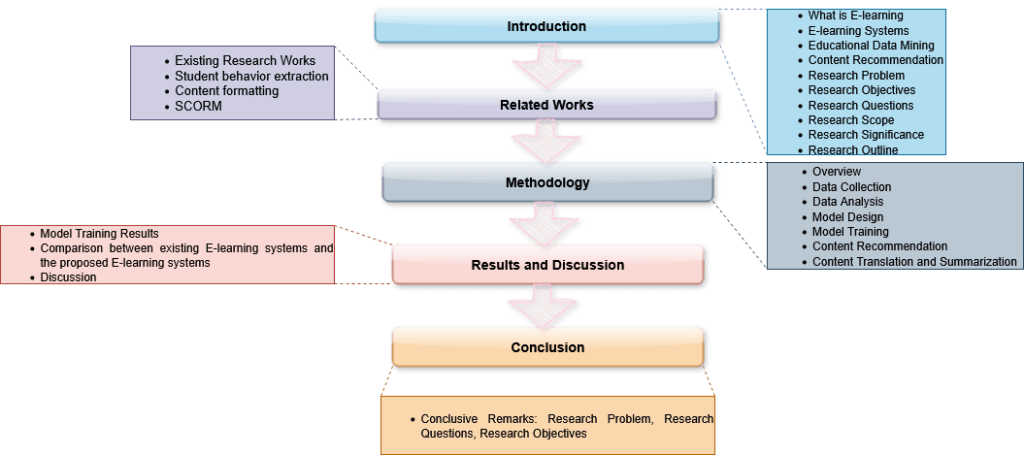
Section 1 provides a comprehensive introduction to the entire research, setting the foundation and context for the study. Following this, Section 2 delves into the related literature, where it reviews previous research efforts relevant to the proposed study. This section not only summarizes earlier work but also critically highlights the limitations and drawbacks that have been identified, thereby establishing the need for current research. The methodology of the study is detailed in Section 3, which emphasizes the novel approach and procedures that define this research. This section carefully explains the specific methods employed, underscoring the innovations introduced to address the gaps found in prior studies. Upon implementing the methodology, the research progresses to Section 4, which presents the results obtained from the experimental or analytical processes. This section also includes an in-depth discussion that interprets the findings, considering both the current results and the shortcomings noted in previous work, thus providing a clear comparison and justification for the research’ contributions. Finally, the study concludes with a meaningful conclusion section that synthesizes the key outcomes, addressing the initial research questions, problems, and objectives. This concluding part not only summarizes the study’s achievements but also reflects on its significance, implications, and potential directions for future research.
Figure 1 shows the outline throughout the research flow.
2. Related Works
The following sections state the similar works that were done on the existing works for the proposed research system, the topics of Student behavior extraction, content formatting, and SCORM. Finally, research remarks have been clarified according to the whole literature review.
2.1. Existing Research Works
Many studies have discussed intelligent E-learning management systems to enhance user experience. In [1] and [2], both focus on personalized recommender systems, with [1] emphasizing the role of these systems in overcoming information overload and [2] proposing an intelligent profiling system to recommend courses based on user preferences. The management of learning information [3] was discussed in E-learning systems, emphasizing the need for interoperability and proposing an Open Education Service Architecture.
2.1.1. Intelligent E-learning Management Systems
An intelligent adaptive E-learning model [4] has been proposed to classify learners and to provide adaptive con- tent. Another intelligent E-learning Management system [5] has been introduced to enhance multi-agents that can be used to organize content resources and provide personalized access.
2.1.2. E-learning Management Systems for enhanced user experience
A range of studies have been done regarding the usage and experience of users for various E-learning management systems. An improved E-learning system [6] was designed with features such as online material upload, one-on-one interaction, and real-time communication with lecturers. An E-learning management system [7] was proposed using web services, focusing on features like content and learning management, delivery management, and access control. These studies collectively highlighted the requirement of user experience in E-learning management systems and the potential for improvement through enhanced features and usability.
2.1.3. Existing Research Improvements
Table 1 shows how improvements should be focused on. By considering the above research works improvements, the proposed research project has been focused on considering those improvements which have to be focused on existing research works. A methodology has been decided on what we can do to build the research project. According to that methodology, the following research works have been highlighted.
2.2. Student behavior extraction
E-learning had allowed students to engage in course con- tent and develop their learning behaviors. There were several key categories that highlight E-learning behaviors [8, 9]. Learning preparation meant activities like accessing the course homepage, navigating to course pages, and reviewing supplementary materials that prepare students for learning. Knowledge acquisition behavior means behaviors focused on actively acquiring knowledge, such as accessing course content, watching videos, and participating in discussions.
Table 1: Existing Research Improvements
Research work | Improvement that should be focused |
[1] | Personalized learning content formats and content versions of users |
[2] | Content-based and collaborative filtering recommendation techniques are combined |
[10] | How to arrange contents according to user requirements |
[3] | The advancement of the E-learning systems which must be spread and that should be implemented to gain user interest in E-learning systems |
[4] | With a minimum amount of data during the classification has been done. Only KNN algorithm has been used with lack of parameters |
[11] | A model and a system based on Student-Centered based E- learning Environments |
[6] | An improvement in making this research considering videos, and automatic course selection according to students registered level |
Studies have been done on individual learning styles and approaches impact E-learning behaviors and performance [9, 12]. There are some factors that can be reasoned to influence their E-learning behaviors and intentions [9].
The E-learning engagement levels of students could be examined with the extracted behavior from the contents. There are several research to highlight features [13, 14, 15] on behavioral extraction of students. Emotions [16, 17] and moods [18, 19] of students can be extracted from student engagements using online lecture videos.
2.2.1. Data Gathering
The data were gathered from the E-learning system before any information. This could be done using two ways such as active and passive information gathering. Active information gathering would be done by observing user interactions surveys, quizzes, tutorials, assignments [15], lab practicals, and exams. Passive information gathering could be done by observing user interactions using the E-learning systems.
2.2.2. Pattern Recognition
Several data are not in order, because of that they should be processed and sorted to extract meaningful information.
Unsupervised clustering algorithms [20, 21] or supervised machine learning algorithms [14, 21, 22] were used to identify patterns from a large collection of data.
2.2.3. Clustering Algorithms
Clustering algorithms, particularly K-means, are widely applied in E-learning for grouping similar learning behaviors and enhancing personalization. They support adaptive systems, identify struggling students, and improve content delivery [23, 15, 24]. Techniques also predict learning styles using log files [25], categorize students by behavior [26], and analyze learning preferences via weblog mining [27]. These methods enhance academic performance and optimize resource delivery [28].
2.2.4. Pattern recognition with Supervised Machine Learning
Supervised learning techniques like neural networks and decision trees have been used to analyze student learning behaviors and tailor teaching strategies [29, 14]. E-learning systems have also leveraged data mining and big data for pattern recognition and predictive analytics [30], while challenges and credentials were explored using process mining methods [31].
2.2.5. Interest Recognition
Interest Recognition involved analyzing user interactions with content, including factors like duration and click frequency, as well as feedback on interactive features. Several earlier studies were conducted [32] with respect to this issue, among which had been used to identify factors affecting student acceptance for E-learning and their intension to usage of E-learning. Several patterns [33] were identified in the behavior of students while learning several things in different incidents. Data collection and the center of interest construction [34] were done by two modes.
2.2.6. Scoring User interactions in the systems
User engagement can be assessed by scoring interactions based on their relevance to the user’s content interests. Studies have examined such systems [35] analyzed engagement and interactivity using scoring methods, while [36] evaluated interaction through usage metrics and system usability scores.
2.3. Content formatting
Personalized content recommendations should be implemented upon determining user interest levels and behaviors. There were various methods for achieving this, including organizing content with templates, dynamically arranging content using templates, translating content across different media types, and summarizing content.
2.3.1. Content arrangements with templates
A content customization strategy can involve templating for different skill levels—novices benefit from visual aids and simplified language, while experts prefer dense, detailed texts [37]. Prior efforts emphasized aligning content with E-learning standards and interactive digital formats [38].
2.3.2. Dynamic Content arrangements
A system can dynamically organize content based on user preferences to enhance engagement. Prior work applied such adaptive content arrangement to address variations in learner behavior, goals, styles, and knowledge levels [39].
2.3.3. Content translation across media
Content creators on an E-learning system were often experts in their field but may lack the expertise, resources, or time to create engaging multimedia content. Using machine learning models and existing content enabled the generation of created multimedia content for specific users. Research had demonstrated that combining machine translation systems and translation technologies, could enhance performance of students and translation quality in educational settings [40].
2.3.4. Content Summarization
Advanced users who already had knowledge of the given domain, but they required the core content of the given lesson, or a blog presented in a condensed manner. The content summarization had been used [41] to aid both individual and collective learning endeavors. Content summarization [41] had been employed to support learning activities, understand user proficiency and annotations, and generate multiple summaries of the same document created to different skill levels.
2.3.5. Personalized content recommendation
Previous E-learning research has explored personalized learning using mathematical models [42], sentiment-aware recommendations [43], and solutions for integrity issues in learning platforms [44]. Recommendation system architectures leveraging ontologies and rule-based reasoning were proposed [45], along with broad reviews of personalized recommendation techniques [46]. Further enhancements included content matrices, logistic regression, deep learning, and flexible frameworks for adaptive course design.
Finally, in [47, 48], emphasis was placed on employing machine learning-based methods which allow for personalized learning experiences by selecting suitable relevant shaping activities. For course selection recommendations to E-learners and instructors, they utilized Natural Language Processing methods as well as semantic analysis approaches [49].
These personal recommendations, such as those based on the search history [50] of users, are highly relevant to individual users. An E-learning system had been specially designed to improve student learning by creating recommendations that embed latent skill based on historical interactions [51] between students, lessons, and assessments. This probabilistic framework for students and educational material could suggest customized lesson sequences to assist students in getting ready for evaluations.
2.4. SCORM
2.4.1. Overview
The article [52] described the main features, technical books, history, and support of Sharable Content Object Reference Model (SCORM), standards and specifications collections that enable interoperability of learning content across different systems and tools. The paper [53] presented a SCORM digital teaching resource management model, comprising of four parts: content aggregation model, run time environment, sorting and navigation, and collaborative filtering engine. It also included the design and implementation of SCORM related digital teaching resource library system. That system is based on collaborative filtering technology with performance evaluation using a data set of movie ratings. The results showed that the system can improve the learning efficiency and satisfaction of the learners. The article [54] explained that SCORM combines three specifications: content packaging, run-time environment, sequencing and navigation. It also lists the benefits of SCORM, such as compatibility, reusability, personalization, and tracking. It integrates contributions from organizations like IMS Global Learning Consortium, AICC, and ARIADNE, enabling multimedia presentations for distance learning across platforms [55]. Versions like SCORM 1.0 and 2004 (also known as 1.3) focus on packaging, delivery, and tracking of learning objects [55].
2.4.2. Core components
SCORM comprises three main components: Content Aggregation Model (CAM), Run-Time Environment (RTE), and Sequencing and Navigation (SN).
- Content Aggregation Model (CAM) This specification defines how learning content is structured and packaged. The CAM establishes the framework for Sharable Content Objects (SCOs) and Assets, which serve as the fundamental building blocks of SCORM- compliant content. SCOs are standalone, reusable learning modules that can communicate with the Learning Management System (LMS), while Assets are static content collections that do not require LMS communication. [55, 56].
- Run-Time Environment (RTE) The RTE specification governs the communication protocols between learning content and the LMS during execution. It implements a standardized JavaScript API that enables content to exchange data with the hosting system, facilitating learner tracking, progress monitoring, and content state management [55].
- Sequencing and Navigation (SN) Available in SCORM 2004, this component provides sophisticated content flow control mechanisms. It enables the creation of adaptive learning paths based on learner performance, prerequisites, and pedagogical rules defined by instructional designers [57].
SCORM represents a foundational achievement in e- learning standardization, providing technical specifications that have enabled widespread interoperability and content reusability. While the standard faces contemporary challenges related to mobile compatibility, content flexibility, and integration with emerging technologies, ongoing academic research continues to address these limitations through innovative architectural approaches, middleware solutions, and enhanced metadata models.
The technical depth of SCORM’s specifications, from its JavaScript API implementation to its sophisticated sequencing mechanisms, demonstrates the standard’s robust engineering foundation. However, the emergence of newer standards like xAPI and the evolving demands of modern e-learning environments suggest that SCORM’s future lies in architectural evolution rather than incremental enhancement.
2.5. Research Remarks
A comprehensive literature review using many research works has been conducted in the areas of students’ behavior extraction and content recommendation. The field of student behavior extraction covers several key areas including data gathering, pattern recognition, clustering algorithms, interest recognition, and scoring user interactions in the systems. On the other hand, in the realm of content recommendations, significant focus is placed on content arrangements with templates, dynamic content arrangements, content translation across media, content summarization, and personalized content recommendation as discussed in the literature review that was conducted. Additionally, further research findings related to other works have also been highlighted.
From the related works done so far, we can conclude that many research works have been done in this domain. Existing research findings are inadequate in enhancing user interest in E-learning content. From the research findings, it can be seen that there is room for improvement. In content recommendation systems, that target user interests. Thus, in the proposed system research will be done in the direction of user interest enhancement to extract data by personalized content recommendation
3. Methodology
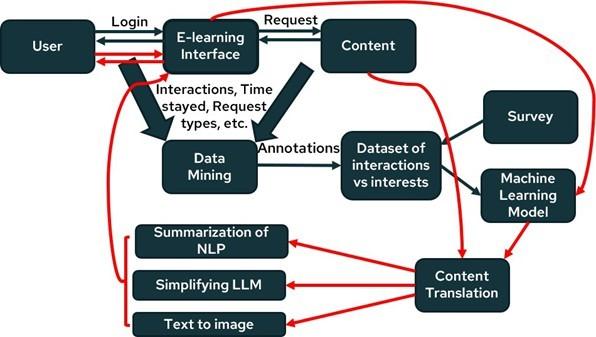
The prevalence of online learning is steadily increasing, contributing to the establishment of a knowledgeable world. In Sri Lanka, there is a notable trend wherein students predominantly utilize E-learning systems for their educational needs. The E-learning interface plays a crucial role in facilitating student interaction and exploration of diverse topics or subjects of interest. In this context, when a user expresses interest in a particular topic, the E-learning inter- face promptly retrieves relevant details and presents them to the user. As a result, it will be generating valuable data that serves as the foundational basis for the improvement of the user experience. This academic behavior highlights the significance of E-learning systems in Sri Lanka, that focusing their role in providing students with interactive learning contents in variety of subjects. The information gathering and data collection support the enhancement of the E-learning experience for users.
This E-learning system can adapt content based on learning styles. For example, the learners can get advantages from multimedia content, while some others can get advantages from simulations. The recommendations can be adjusted based on monitoring learner behavior. If a learner struggles with a particular type of content, the system can suggest alternative formats or additional resources. The in- sights into learner preferences can be measured and learner recommendations can be refined based on time spent on tasks and interaction frequency.
The completed research project will flow as presented in Figure 2. A comprehensive database was created by collecting data and integrating survey responses during the training phase. This dataset was processed and used to train the model, focusing it to understand build relationships between user interactions, requested content, and user preferences. After this training, the model [58, 59, 60] was developed to identify patterns and conditions governing the recommendation of useful content types based on learners past interactions in the E-learning system. At the completion of the training phase, when users access the content of the E-learning interface, the E-learning system interacts with the trained model, instead of directly requesting the content from the system. The model prompts the learning conditions and patterns to identify the most appropriate type of content according to the user’s specific requirements and preferences.
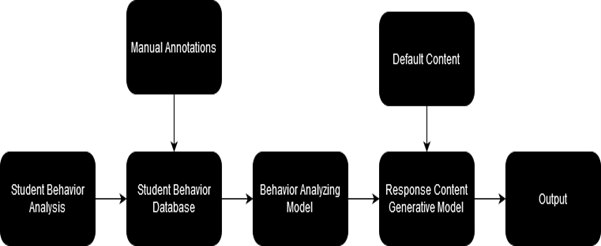
To meet user preferences, a content translation algorithm adapts material into the desired format or learning style—such as converting text to audio for users who prefer auditory content.
Figure 3 [60] presents a graphical representation of the complete model throughout the research.
3.1. Data Collection
In the data collection procedure, data were collected in different ways, by surveying to gather user responses to- wards E-learning, a survey to analyze students’ interactions towards the contents of E-learning, and from the Moodle log data.
3.1.1. Survey to analyze student’s interactions towards the contents on E-learning
In the pursuit of understanding students’ preferences for learning content, the data were collected using a survey on various aspects of academic performance. Approximately 1000 users actively participated in this survey, providing valuable insights into their preferences. The survey focused on three key dimensions: the preferred format for learning content, the preferred content version, and the preferred content presentation style.
Preferred Format for Learning Content: students have stated their preferences according to the learning content format that is collected according to their academic performance rate. This can be used to identify the medium that delivers educational materials.
Preferred Content Version: students expressed their preferences concerning their most favorable content version. This includes their preferences in summarized content and content presented more in-depth.
Preferred Content Presentation Style: students’ preferences on the content were also gathered using the survey. They implied their responses on content to be conveyed in a story format or presented more straightforwardly.
The survey results contribute valuable insights for educators and instructional designers seeking to optimize con- tent delivery in line with student preferences. From around 1000 users, Table 2 shows how many users preferred various learning contents. Table 3 shows how many users are preferred for various learning contents according to user performance rating.
From around 1000 users, Table 4 shows how many users preferred content that is summarized or explained. Table 5 shows how many users preferred content that is summarized or explained according to user performance rating.
From around 1000 users, Table 6 shows how many users preferred content that is the straightforward manner or story format. Table 7 shows how many users preferred content that is straightforward manner or story format according to user performance rating.
3.1.2. LMS log data
In the context of analyzing user behavior within an E-learning module, a sample dataset was required to understand user attraction and involvement in specific tasks. For this purpose, log data was collected from the Moodle platform in Sri Lanka.
The gathered log data encompassed approximately 47,647 events recorded by users interacting with the module. Each event was associated with a specific status, reflecting the nature of the user’s action. The statuses were identified within the module. Those statuses are added, assigned, created, deleted, downloaded, enrolled, graded, joined, posted, removed, restored, searched, started, submitted, subscribed, unassigned, updated, uploaded, and viewed which are done by the users. This academic categorization provides a structured overview of log data, enabling a systematic analysis of user interactions and behaviors within the E-learning module. The user’s reaction according to each status has been shown in Table 8.
Table 2: No of users preferred for various learning contents
The preferred format for learning content | No of Users |
Image-based | 203 |
Audio-based | 123 |
Video-based | 492 |
Text-based | 182 |
Table 3: No of users preferred for various learning contents according to user performance rating
Preferred content format | No of Users | ||||
Rating 1 | Rating 2 | Rating 3 | Rating 4 | Rating 5 | |
Image-based | 6 | 109 | 68 | 13 | 7 |
Audio-based | 3 | 18 | 29 | 40 | 33 |
Video-based | 69 | 143 | 174 | 64 | 42 |
Text-based | 15 | 26 | 35 | 43 | 63 |
Table 4: No of users preferred content that is summarized or explained
Preferred content version | No of Users |
Summarized content | 604 |
Explained content | 396 |
Table 5: No of users preferred for various learning content versions according to user performance rating
Preferred content version | No of Users | ||||
Rating 1 | Rating 2 | Rating 3 | Rating 4 | Rating 5 | |
Summarized content | 52 | 83 | 104 | 169 | 196 |
Explained content | 138 | 101 | 62 | 53 | 42 |
Table 6: No of users preferred content that is straightforward manner or story format
Preferred content format | No of Users |
Straightforward manner | 431 |
Story format | 569 |
Table 7: No of users preferred content that is straightforward manner or story format according to user performance rating
Preferred content format | No of Users | ||||
Rating 1 | Rating 2 | Rating 3 | Rating 4 | Rating 5 | |
Straightforward manner | 52 | 65 | 74 | 109 | 131 |
Straightforward manner | 179 | 144 | 92 | 83 | 71 |
Table 8: No. of responses on statuses
Status | No of Users |
Added | 116 |
Assigned | 61 |
Created | 2272 |
Deleted | 768 |
Downloaded | 4 |
Enrolled | 61 |
Graded | 122 |
Has | 87 |
Joined | 752 |
Posted | 2975 |
Removed | 2 |
Restored | 3 |
Searched | 17 |
Started | 69 |
Submitted | 76 |
Subscribed | 341 |
Unassigned | 2 |
Unsubscribed | 13 |
Updated | 2878 |
Uploaded | 23 |
Viewed | 37023 |
In the realm of educational events, various attributes can be systematically categorized to facilitate a comprehensive understanding and analysis within the system. This academic categorization establishes distinct types, each serving a specific purpose. The identified categories encompass courses, discussion, comment, tag, user, role, grade item, override, page, group, module, post, attempt, submission or meeting.
This section shows a systematic framework that enhances the organization and interpretation of data related to educational events. It backbones to a more structured approach to manage and analyze various aspects of user interactions and behaviors within the educational context.
3.2. Data Analysis
As part of our initiative to analyze user engagement in E-learning, we used a Kaggle dataset of student activity logs to test and refine our code before applying it to the original data. This preliminary analysis as shown in Figure 4 helped identify key patterns and variables influencing user interactions. Using the Kaggle dataset allowed us to fine-tune model parameters, improving both the accuracy and reliability of our training process.
Figure 5 represents a correlation matrix for online class- room data. The trained dataset is given as a correlation matrix in figure 6.
In an online classroom setting, the dynamics of interactions among participants can be diverse. Various factors contribute to this variability, such as the nature of the posts generated during these interactions. One key aspect is the propensity of participants to initiate creative discussions. Analyzing the dataset reveals a distinction between posts categorized as either good or bad, shedding light on the overall quality of the contributions.
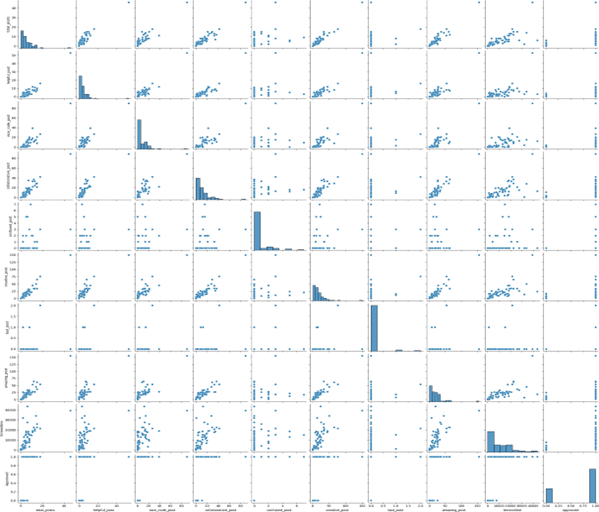
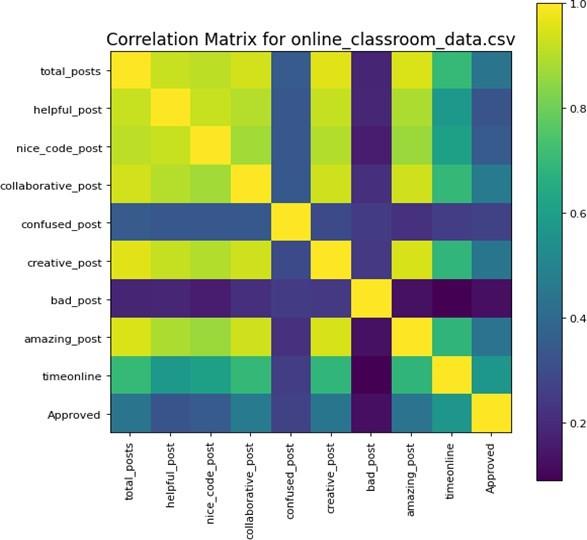
Upon examining the entirety of posts, it becomes apparent that the number of posts deemed helpful is notably scarce. Curiously, there is a lack of posts categorized as bad when compared to the volume of helpful posts. This imbalance suggests a generally positive and constructive atmosphere within the online classroom, where participants are more inclined to assist rather than engage in detrimental interactions.
The online time duration is high when considering the dataset in addition to the total number of posts. This high- lights a high level of engagement among participants that reflects an active online learning community.
It is observed that the frequency of creative posts is note worthy. The dataset also highlights a high occurrence of categorized posts also. This is a reason to suggest the online classroom system that can be used to foster creativity and positive engagement with useful information and content. This initial training was using the XGBoost algorithm that has been conducted on this dataset. The resultant model provides valuable points into the classification of posts. This training process obtained specific parameters and classification values. This stage offered a quantitative condition within the online classroom that gives a foundation for further analysis and refinement of the learning model.
Initially, the XGBoost algorithm was used for model training, but due to unsatisfactory accuracy, it was replaced with the Random Forest algorithm, which provided improved predictive performance. After initial training, data cleaning was conducted to remove unnecessary log columns like system and mentor logs, streamlining the dataset.
Survey insights guided the assignment of weights to user preferences across various content types (videos, audio, animations, text) and formats (summarized or detailed, straightforward or story-driven). Manual data annotation further enhanced the training dataset, and the Random Forest model achieved an 80/20 traintest split, effectively validating its performance.
In-depth analysis of this refined dataset, organized in a CSV file, revealed patterns and relationships, allowing accurate weight assignments based on user preferences. This structured framework supports a robust content recommendation system, enabling more precise and personalized content delivery based on user specific features and preferences.
3.3. Model Design
It was required to calculate the weight to recommend the content. Then, an equation was created to calculate the weight. The following factors were considered when creating the equation 1.
𝑈𝑟 − 𝐶𝑟 = 𝐴𝑟 (1)
- Ur- User rating
- Cr- Content rating
- Ar- Aggregate response value
3.3.1. User rating
The user rating weights are generated using the module’s log data. Initially, weights were assigned arbitrarily based on user responses. These responses were collected from the relevant Learning Management System (LMS) platform and recorded by the users themselves. The obtained weights are mentioned according to the dataset. It is shown in Table 9.
Table 9: No of weights on statuses
Responses | Weights |
Created | 5 |
Posted | 5 |
Updated | 5 |
Joined | 4 |
Subscribed | 3 |
Added | 3 |
Submitted | 3 |
Uploaded | 3 |
Assigned | 2 |
Graded | 2 |
Created | 2 |
Deleted | 1 |
Downloaded | 1 |
Enrolled | 1 |
Removed | 1 |
Restored | 1 |
Searched | 1 |
Started | 1 |
Submitted | 1 |
Unassigned | 1 |
Unsubscribed | 1 |
Viewed | 1 |
Table 10 presents the responses and their corresponding weights. Specifies the weights for each component of the Learning Management System (LMS) based on the data set. The random weights assigned to these components are shown in Table 10.
Table 10: No of components on weights
Components | Weights |
Assignment | 4 |
File | 3 |
File submission | 3 |
Folder | 2 |
Forum | 3 |
Page | 2 |
Quiz | 5 |
System | 1 |
URL | 2 |
Wiki | 2 |
Zoom meeting | 2 |
Initial values were arbitrarily assigned based on heuristic criteria, which considered the impacts of data collection and analysis during selection. Subsequently, a recurrent learning approach was implemented to fine-tune these values using the collected responses. Finally, the user rating values are generated. Table 11 displays the user ratings according to the defined event user rating values.
Table 11: User rating value on events
Events | User rating value |
A file has been uploaded | 3 |
A submission has been submitted | 3 |
Clicked joining meeting button | 2 |
Comment created | 2 |
Course activity completion updated | 2 |
Course module updated | 1 |
Course module viewed | 1 |
Discussion created | 2 |
Discussion viewed | 2 |
Feedback viewed | 1 |
Group member added | 1 |
Post created | 2 |
Post updated | 2 |
Question updated | 2 |
Question viewed | 2 |
Quiz attempt reviewed | 1 |
Quiz attempt started | 4 |
Quiz attempt submitted | 5 |
Quiz attempt summary viewed | 2 |
Submission updated | 2 |
Wiki page viewed | 1 |
3.3.2. Content rating
The Content Rating (Cr) value is assigned randomly through an analysis of the data gathered on various learning content formats. This assignment considers factors such as the performance rating (which evaluates how well the content performs in terms of user engagement or effectiveness) and the preferred content version (which reflects users’ favored formats or styles of the material).
Table 12 illustrates how the preferred content versions and their associated weights vary, based on the insights from the “Data Collection” section. This table provides a detailed breakdown to show the relationships and variations in these elements.
Table 12: preferred content version and weights
Preferred Content Version | Weights |
Image based | 2 |
Video based | 3 |
Audio based | 4 |
Text based | 5 |
If the user performance rating is nearly 4, and 5 summarized content will be given. If the user performance rating is nearly 1, 2, and 3 explained content will be given.
3.3.3. Aggregate Response Value
The aggregate response values are generated using a random forest algorithm, which is a machine learning ensemble method that builds multiple decision trees and combines their outputs for more accurate predictions. This step creates initial values based on the available data.
Subsequently, a recurrent learning approach—such as recurrent neural networks (RNNs) or similar iterative optimization techniques applied to finetune these values, incorporating insights from the specific content formats (e.g., videos, texts, quizzes, or interactive modules) to improve accuracy and relevance.
The resulting aggregate response value serves as a metric to represent pairwise relationships, capturing interactions and compatibility between different types of users (e.g., based on their preferences, engagement levels, or roles) and various content types within the system.
Table 13 displays these aggregate response values, organized according to the predefined content formats, pro- viding a visual summary of how these relationships are quantified.
Table 13: Aggregate Response Values
Aggregate Content Format | Aggregate Response Value |
Image based + Summarized | -3 |
Image based + Explained | -2 |
Video based + Summarized | -1 |
Video based + Explained | 0 |
Audio based + Summarized | 1 |
Audio based + Explained | 2 |
Text based + Summarized | 3 |
Text based + Explained | 4 |
3.4. Model Training
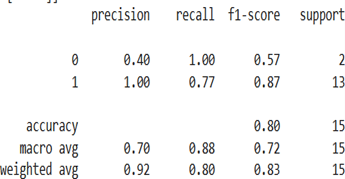
A comprehensive comparative evaluation of XGBoost and Random Forest algorithms was conducted using critical performance metrics including precision, recall, F1 score, and accuracy. This systematic analysis revealed that Random Forest emerged as the superior model, demonstrating greater reliability and robustness compared to XGBoost. Random Forest’s ensemble approach, which combines multiple decision trees through bootstrap aggregating, contributed significantly to its enhanced performance by naturally reducing variance and providing better generalization to unseen data. The algorithm’s ability to handle high- dimensional data without extensive feature engineering, combined with its inherent robustness to noise and outliers, made it particularly suitable for complex datasets while providing valuable feature importance scoring capabilities While XGBoost showed competitive performance through its gradient boosting methodology, it ultimately required more extensive hyperparameter tuning and computational resources compared to Random Forest’s simpler configuration requirements. XGBoost’s sequential tree-building approach, where each tree corrects errors from previous ones, provides excellent predictive capability but demands careful optimization to prevent overfitting. Random Forest’s parallel tree construction enables efficient scaling and demonstrates lower sensitivity to hyperparameter settings, making it more accessible for practitioners while offering superior interpretability through feature importance scores and individual tree visualization capabilities.
Following initial model deployment, comprehensive user feedback was systematically collected through multiple channels including direct surveys, usage analytics, and performance monitoring systems to evaluate real-world performance beyond traditional statistical metrics. Based on this feedback, the model underwent strategic retraining to address identified performance gaps and enhancement opportunities, exemplifying modern machine learning best practices where continuous improvement drives sustained effectiveness. This iterative refinement process incorporated both quantitative performance metrics and qualitative user insights, ensuring that model improvements addressed both statistical accuracy and practical utility while maintaining alignment with user expectations and business requirements.
The successful integration of user feedback into model improvement processes highlights the importance of establishing robust feedback loops in production machine learning systems. Systematic feedback loops with auto- mated triggers for retraining based on performance degradation thresholds enable proactive model maintenance and sustained relevance over time. This evaluation demonstrates that algorithm selection must be guided by specific use case requirements rather than general performance benchmarks, considering factors such as data characteristics, performance requirements, interpretability needs, and operational constraints. The comprehensive approach of combining rigorous comparative evaluation with continuous user feedback integration represents best practices in modern machine learning deployment and maintenance, ensuring sustained model effectiveness through iterative alignment with real-world usage patterns.
3.5. Content Recommendation
According to the aggregate response value, the content was recommended. The random forest algorithm was tested in this context. The aggregate response value is given according to the user rating and the content rating. That has been shown in Table 14.
3.6. Content Translation and Summarization
The process described involves a comprehensive approach to multimedia content analysis and summarization, focusing various tools and methodologies. The workflow encompasses translation, segmentation, image processing, deep learning, and natural language processing techniques. Initially, content translation is executed based on the resultant weight. Videos are transcribed into text format according to user preferences. A summarization process is applied to distill key information for high performing individuals, while low performing individuals receive a more detailed explanation, accompanied by generated images to enhance understanding.
MoviePy (Python) is used to segment audio and video data, converting video frames into images for training with Deep Image Prior (DIP) to extract keywords and identify objects. A large language model then generates transcrip- tions, removes redundancies, and produces a consolidated image. BART (Google) summarizes content, while Ope- nAI’s API aids in segment explanation. Vision API handles image generation, and a speech-to-text tool processes audio separately. Outputs—including explanations, summaries, and images—are delivered via SCORM for standardized, educational use.
In essence, the described process integrates various tools and methodologies to deliver a sophisticated multimedia analysis and summarization system, catering to diverse user preferences and levels of expertise.
4. Results and Discussion
The model was designed using the user rating value, content rating value, and aggregate response value. The user rating weights were generated by training the log data using recurrent learning. The content rating weights were generated by analyzing the data gathering of learning content formats. Finally, aggregate response values were generated based on a random forest algorithm. Those values were created to fine-tune those values from the content format using recurrent learning. Using the XG-Boost algorithm and Random Forest algorithm, the model was trained. The content was recommended according to the aggregated response value. Then this model was used to build the E-learning system by assigning the SCORM standard.
Table 14: Content recommendation according to the aggregated response value
Content Type | Content Rating | User Rating | Aggregated Value | Recommended Output |
Text based | 5 | 1 | 4 | Text based + Explained |
Text based | 5 | 2 | 3 | Text based + Summarized |
Text based | 5 | 3 | 2 | Audio based + Explained |
Text based | 5 | 4 | 1 | Audio based + Summarized |
Text based | 5 | 5 | 0 | Video based + Explained |
Audio based | 4 | 1 | 3 | Text based + Summarized |
Audio based | 4 | 2 | 2 | Audio based + Explained |
Audio based | 4 | 3 | 1 | Audio based + Summarized |
Audio based | 4 | 4 | 0 | Video based + Explained |
Audio based | 4 | 5 | -1 | Video based + Summarized |
Video based | 3 | 1 | 2 | Audio based + Explained |
Video based | 3 | 2 | 1 | Audio based + Summarized |
Video based | 3 | 3 | 0 | Video based + Explained |
Video based | 3 | 4 | -1 | Video based + Summarized |
Video based | 3 | 5 | -2 | Image based + Explained |
Video based | 3 | 5 | -2 | Image based + Explained |
Image based | 2 | 1 | 1 | Audio based + Summarized |
Image based | 2 | 2 | 0 | Video based + Explained |
Image based | 2 | 3 | -1 | Video based + Summarized |
Image based | 2 | 4 | -2 | Image based + Explained |
Image based | 2 | 5 | -3 | Image based + Summarized |
To do the implementation of the system, it shows how the results were generated, the following sections consist of model training results, user-interface results, and the E-learning system with SCORM standard, and a comparison between the current E-learning system & the proposed E-learning system.
4.1. Model Training Results
Initially, the model was trained from the data annotated and processed from the log file dump of Moodle for student behavior analysis. The annotations were done with the results from various surveys and heuristic rules. Following is the loss graph for the training and testing curves of the model which was trained using the random forest algo- rithm. Figure 7 is the initial graph that trained and tested the existing data.
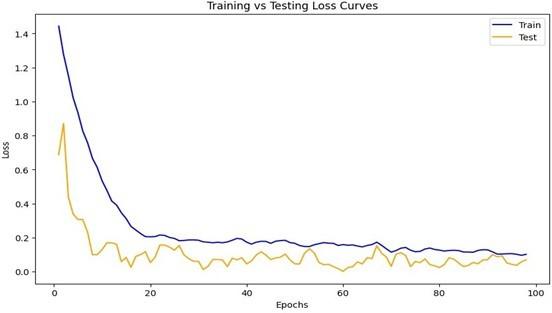
After training and testing, there was a 73.9964% train accuracy value and a 63.1636% test accuracy value. The following graphs of Figure 8 represent that.
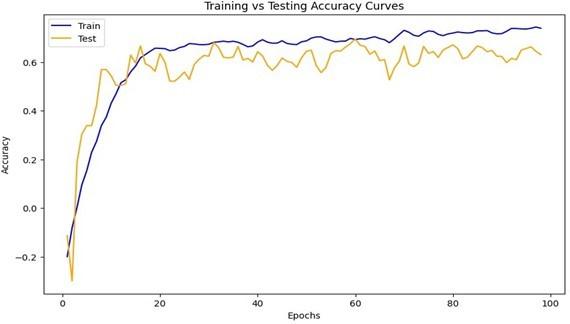
The simulated dataset was given to users, their feedback data were collected. Those data were retrained again. The retrained loss graph is shown in Figure 9.
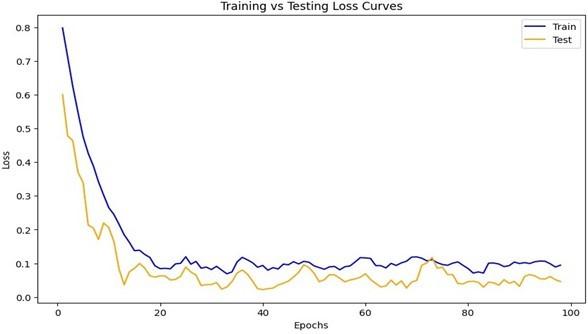
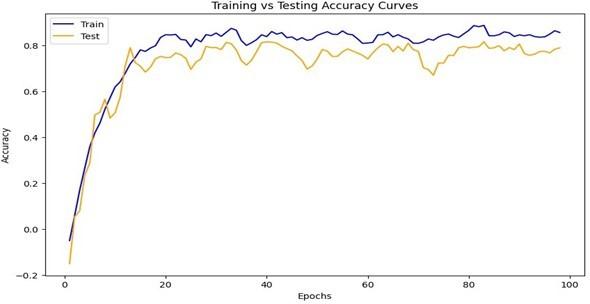
After retraining and testing, there was an 85.5848% retraining accuracy value and a 78.9071% test accuracy value. The following Figure 10 graphs represent that.
4.2. Comparison between existing E-learning systems and the proposed E-learning systems
Table 15 shows the comparisons between existing and proposed e-learning systems.
4.3. Discussion
4.3.1. Multi-Dimensional Data Integration and Model Performance Analysis
The research demonstrates a comprehensive approach to data collection and analysis by integrating multiple data sources to understand user behavior and preferences in e-learning environments. Survey data collection revealed critical insights into user content preferences, with findings showing that a significant proportion of users prefer video-based learning content over other formats, and users consistently favor summarized content rather than detailed explanations. Furthermore, survey responses indicated a strong preference for story-formatted content delivery rather than straightforward presentation methods, highlighting the importance of narrative-driven learning approaches.
Log data integration complemented survey findings by providing objective behavioral analytics that tracked user interactions, session duration, content engagement patterns,
Table 15: Comparison between existing E-learning systems & proposed E-learning systems
Existing E-learning Systems | Proposed E-learning System |
Personalized learning environments were not considered | Personalized learning content formats and content versions of users were used |
Content recommendation was not considered based on user interactions | A combination of content-based and collaborative-based rec- ommendation filtering techniques were used |
User requirements were not considered | How to arrange contents according to user requirements was considered |
User learning interests were not considered | This system was implemented to gain user interest in E- learning systems |
A high amount of data was not collected and trained | A maximum amount of data during the classification has been done. XGBoost and random forest algorithms were used |
Student-centered E-learning Environments have been not concerned | A model and a system based on Student-centered E-learning Environments have been built |
Multiple learning content versions have not been concerned | An improvement has been considered in making this research considering videos, and automatic course selection according to students registered level |
and learning path navigation. This multi-source data approach enabled the researchers to capture both subjective preferences through surveys and objective behavioral pat- terns through system logs, creating a more comprehensive understanding of learner behavior than traditional single- source methodologies. The integration of these diverse data streams allowed the calculation of performance ratings and content ratings, which served as foundational input for the recommendation algorithm.
4.3.2. SCORM Standards Implementation and Content Transformation
The novelty of this research extends to its SCORM- compliant content delivery system, which enables standardized tracking and reporting across different learning management systems. SCORM (Sharable Content Object Reference Model) integration ensures that the recommended content maintains interoperability while providing comprehensive tracking capabilities including completion status, quiz results, time spent on modules, and detailed learner interaction data. The system’s innovative content transformation capabilities allow dynamic conversion between multiple content modalities based on user preferences: text content can be converted to audio format, different text formats can be transformed into summarized or explained versions, and video content can be adapted to audio-only formats with transcription capabilities. This multimodal content adaptation, delivered through SCORM standards, represents a significant advance over traditional recommendation systems that typically focus on single content types.
4.3.3. SCORM Standards Implementation and Content Transformation
The reported accuracies (73.99% → 78.90%) show improvement after retraining, but baseline comparisons are missing. How does the model compare with standard/popular recommendation baselines (e.g., collaborative filtering, matrix factorization, deep learning-based recommenders)? The research achieved notable performance
improvements through iterative model refinement, with training accuracy increasing from 73.99% to 85.58% and testing accuracy improving from 63.16% to 78.90% after retraining. However, the evaluation methodology presents significant limitations in its comprehensiveness. The results only include accuracy metrics, and it would be beneficial to have other types of metrics as well, like precision, recall, and F1 score. Standard recommendation system evaluation typically employs precision, recall and F1 metrics to assess the quality and coverage of recommendations, with precision measuring the fraction of recommended items that are relevant and recall measuring the fraction of all relevant items successfully retrieved. The absence of these metrics limits the ability to fully assess the system’s performance compared to established baselines such as collaborative filtering approaches, matrix factorization techniques like SVD and SVD++, or advanced deep learning models including autoencoders, neural collaborative filtering, and hybrid deep learning architectures.
4.3.4. Enhanced User Engagement and System Effectiveness
Despite the evaluation limitations, the research demonstrates better user engagement compared to current e- learning systems, with the proposed content recommendation approach generating significantly more user interactions with recommended content. The integration of behav- ioral analysis, multimodal content delivery, and SCORM- compliant tracking creates a comprehensive ecosystem that addresses the multifaceted challenges of modern e-learning environments. This holistic approach contributes meaning- fully to the advancement of intelligent tutoring systems by providing a framework that can adapt to individual learn- ing styles while maintaining standardized tracking and reporting capabilities across various educational platforms.
5. Conclusion
This research presents a novel multimodal content recommendation model that significantly addresses current limitations in e-learning systems by integrating student behavior analysis, learning styles, and content personalization to enhance user engagement and learning outcomes. Despite substantial research in e-learning recommendation systems, existing approaches have shown limitations in effectively capturing user interests and providing personalized content that aligns with individual learning preferences. The novelty of this research lies in its comprehensive integration of both content rating and user rating mechanisms within a unified framework that supports multiple content modalities—text-based, audio-based, image-based, and video-based formats—all delivered through SCORM- compliant standards. The proposed model demonstrates significant performance improvements through iterative refinement, achieving 85.58% training accuracy and 78.90% testing accuracy after retraining, compared to initial results of 73.99% and 63.16% respectively. This substantial accuracy enhancement reflects the model’s sophisticated approach to learning behavior analysis using machine learning techniques that automatically detect learning styles based on behavioral patterns rather than traditional questionnaire- based methods. The research contributes a unique multimodal approach that leverages advanced content-based and collaborative filtering techniques, addressing critical challenges such as data sparsity and cold-start problems commonly encountered in recommendation systems. By incorporating SCORM standards, the model ensures interoperability across different learning management systems while enabling comprehensive tracking of learner progress, engagement metrics, and content interaction patterns. The findings demonstrate how this integrated approach to content recommendation can promote growth in e-learning systems by providing academic and e-learning providers with enhanced tools for creating, designing, and delivering more personalized and effective learning experiences that adapt to individual user preferences and learning behaviors.
5.1. Conclusive Remarks
5.1.1. Research Problem
Everyone has a different capability for learning, and the general content delivery system is not very successful. There is no significant research found on recommending content based on the interest of the subject from the student in current E-learning systems in universities.
The research problem was solved by recommending the content based on user rating and user interest. Table 14 shows how content was recommended based on aggregated value, content rating, and user rating.
5.1.2. Research Questions
- How to identify student interactions and attractions towards the contents of the E-learning?
This research question was solved by using log data and those log data were used to gather student inter- actions towards the contents of the E-learning. Those logs were collected using undergraduate students of Moodle in Sri Lanka. Most of the students are interested in using E-learning systems. There is a high number of students who have user engagement towards the overall E-learning content.
- How to evaluate user interest for the E-learning content?
This research question was solved by doing surveys. A huge number of log data were gathered from Moodle and those log data were used to evaluate user interest in the content. The interactions of students with the E-learning systems have been shown. The greatest number of users preferred video-based learning content, the greatest number of users preferred content version summarized content, and the highest number of users preferred content format story format content.
- How to deliver targeted content to each individual student to interact with students?
This research question was solved according to the user performance and content rating; the targeted content was recommended. It can be shown that recommended output can be given according to user rating and content rating values.
- How to translate content through different media according to the user’s interests such as when given content is in text format and the targeted audience requires the content in audio format to be interested?
This research question was solved according to the user performance rating, lengthy, unclear texts can be converted to summarized texts and explained texts. When the target audience needs the content in audio format, the videos can be converted to audio format and the audio can be transcribed.
5.1.3. Research Objectives
- How to identify user needs and user interactions through mining data
This objective was achieved by analyzing the data obtained from surveys, and user interactions, such as logins, course accesses, content views, and assignment completions, valuable insights that can be obtained regarding user behavior and preferences. This data mining process helped to uncover patterns and correlations, allowing the proposed model to achieve a deeper understanding of individual users and their specific learning requirements.
- How to develop lessons based on user needs to enhance user interest and interact
By analyzing user data—such as preferences, performance, and interactions, the system dynamically created content recommendations to meet each user’s unique needs and interests. This alignment with individual learning styles, performance levels, and goals made the content more relevant and engaging, focusing on the learning process and boosting user interest. By delivering recommended content, the proposed system aims to create a highly engaging learning experience that motivates users to actively participate and explore the content, leading to enhanced user interest and ultimately an improved user experience.
6. Recommendations
In the surveys that were done during the research, most users preferred video-based learning content were found out. Most of the users preferred summarized content rather than explained content and most of the users preferred content story format content rather than straightforward manner content.
7. Future Works
The accuracy of the model can be enhanced by increasing the dataset size and increasing the iterations used to train the model. The system can be further implemented using common cartridge standards. The system can be further implemented as Artificial intelligence-based auto-generation content.
- Sunil, M. Doja, “An improved recommender system for e-learning environments to enhance learning capabilities of learners”, “Proceedings of ICETIT 2019: Emerging Trends in Information Technology”, pp. 604–612, Springer, 2020, doi:10.1007/978-3-030-30577-2_53.
- R. Kaur, D. Gupta, M. Madhukar, A. Singh, M. Abdelhaq, R. Alsaqour, J. Breñosa, N. Goyal, “E-learning environment based intelligent profiling system for enhancing user adaptation”, Electronics, vol. 11, no. 20, p. 3354, 2022, doi:10.3390/electronics11203354.
- S. F. Abd Hamid, N. A. Bakar, N. Hussin, et al., “Information management in e-learning education”, International Journal of Academic Research in Business and Social Sciences, vol. 7, no. 12, pp. 2222–6990, 2017, doi:10.6007/IJARBSS/v7-i12/3625.
- S. Bhaskaran, P. Swaminathan, “Intelligent adaptive e-learning model for learning management system”, Research Journal of Applied Sciences, Engineering and Technology, vol. 7, no. 16, pp. 3298–3303, 2014,
doi:10.19026/rjaset.7.674. - A. E. Amin, “An intelligent synchronous e-learning management system based on multi-agents of linked data, ontology, and semantic service”, International Journal of Intelligent Computing and Information Sciences, vol. 19, no. 1, pp. 25–37, 2019, doi:10.21608/ijicis.2019.62606.
- B. A. Buhari, A. Roko, “An improved e-learning system”, Saudi Journal of Engineering and Technology, vol. 2, no. 2, pp. 114–118, 2017, doi:10.21276/sjeat.2017.2.2.5.
- N. Partheeban, N. SankarRam, “e-learning management system using web services”, “International Conference on Information Communication and Embedded Systems (ICICES2014)”, pp. 1–7, IEEE, 2014,
doi:10.1109/ICICES.2014.7033900. - J. Zhang, F. Qiu, W. Wu, J. Wang, R. Li, M. Guan, J. Huang, “Elearning behavior categories and influencing factors of stem courses: A case study of the open university learning analysis dataset (oulad)”, Sustainability, vol. 15, no. 10, p. 8235, 2023, doi:10.3390/su15108235.
- T. D. Pham Thi, N. T. Duong, “E-learning behavioral intention among college students: A comparative study”, Education and Information Technologies, 2024, doi:10.1007/s10639-024-12592-4.
- M. M. Althobaiti, P. Mayhew, “Assessing the usability of learning management system: User experience study”, “E-Learning, E-Education, and Online Training: Second International Conference, eLEOT 2015, Novedrate, Italy, September 16-18, 2015, Revised Selected Papers 2”, pp. 9–18, Springer, 2016, doi:10.1007/978-3-319-28883-3_2.
- H. B. Santoso, M. Schrepp, R. Isal, A. Y. Utomo, B. Priyogi, “Measuring user experience of the student-centered e-learning environment”, Journal of Educators Online, vol. 13, no. 1, pp. 58–79, 2016.
- P. Zhang, “Understanding digital learning behaviors: Moderating roles of goal setting behavior and social pressure in largescale open online courses”, Frontiers in Psychology, vol. 12, 2021, doi:10.3389/fpsyg.2021.783610.
- F. Qiu, L. Zhu, G. Zhang, X. Sheng, M. Ye, Q. Xiang, P.-K. Chen, “E-learning performance prediction: Mining the feature space of effective learning behavior”, Entropy, vol. 24, no. 5, p. 722, 2022, doi:10.3390/e24050722.
- K. Abhirami, M. Devi, “Student behavior modeling for an e-learning system offering personalized learning experiences”, Computer Systems Science & Engineering, vol. 40, no. 3, 2022, doi:10.32604/csse.2022.020013.
- M. Liu, D. Yu, “Towards intelligent e-learning systems”, Education and Information Technologies, vol. 28, no. 7, pp. 7845–7876, 2023, doi:10.1007/s10639-022-11479-6.
- M. N. Hasnine, H. T. Bui, T. T. T. Tran, H. T. Nguyen, G. Akçapınar, H. Ueda, “Students’ emotion extraction and visualization for engagement detection in online learning”, Procedia Computer Science, vol. 192, pp. 3423–3431, 2021, doi:10.1016/j.procs.2021.09.115.
- N. Gao, W. Shao, M. S. Rahaman, F. D. Salim, “n-gage: Predicting inclass emotional, behavioural and cognitive engagement in the wild”, Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 4, no. 3, pp. 1–26, 2020, doi:10.1145/3411813.
- L. Meegahapola, W. Droz, P. Kun, A. De Götzen, C. Nutakki, S. Diwakar, S. R. Correa, D. Song, H. Xu, M. Bidoglia, et al., “Generalization and personalization of mobile sensing-based mood inference models: an analysis of college students in eight countries”, Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies, vol. 6, no. 4, pp. 1–32, 2023, doi:10.1145/3569483.
- K. Assi, L. Meegahapola, W. Droz, P. Kun, A. De Götzen, M. Bidoglia, S. Stares, G. Gaskell, A. Chagnaa, A. Ganbold, et al., “Complex daily activities, country-level diversity, and smartphone sensing: A study in denmark, italy, mongolia, paraguay, and uk”, “Proceedings of the 2023 CHI conference on human factors in computing systems”, pp. 1–23, 2023, doi:10.1145/3544548.3581190.
- K. P. Sinaga, M.-S. Yang, “Unsupervised k-means clustering algorithm”, IEEE Access, vol. 8, pp. 80716–80727, 2020, doi:10.1109/ACCESS.2020.2988796.
- X. Chen, B. Li, R. Proietti, Z. Zhu, S. J. B. Yoo, “Self-taught anomaly detection with hybrid unsupervised/supervised machine learning in optical networks”, Journal of Lightwave Technology, vol. 37, no. 7, pp. 1742–1749, 2019, doi:10.1109/jlt.2019.2902487.
- N. Kühl, M. Goutier, L. Baier, C. Wolff, D. Martin, “Human vs. supervised machine learning: Who learns patterns faster?”, Cognitive Systems Research, vol. 76, pp. 78–92, 2022,
doi:10.1016/j.cogsys.2022.09.00 - A. Ashraf, M. G. Khan, “Effectiveness of data mining approaches to e-learning system: A survey”, NFC IEFR Journal of Engineering and Scientific Research, vol. 4, 2017.
- A. Moubayed, M. Injadat, A. Shami, H. Lutfiyya, “Student engagement level in an e-learning environment: Clustering using k-means”, American Journal of Distance Education, vol. 34, no. 2, pp. 137–156, 2020, doi:10.1080/08923647.2020.1696140.
- O. El Aissaoui, Y. El Madani El Alami, L. Oughdir, Y. El Allioui, “A hybrid machine learning approach to predict learning styles in adaptive e-learning system”, “Advanced Intelligent Systems for Sustainable Development (AI2SD’2018) Volume 5: Advanced Intelligent Systems for Computing Sciences”, pp. 772–786, Springer, 2019, doi:10.1007/978-3-030-11928-7_70.
- S. Kausar, X. Huahu, I. Hussain, Z. Wenhao, M. Zahid, “Integration of data mining clustering approach in the personalized e-learning system”, IEEE Access, vol. 6, pp. 72724–72734, 2018, doi:10.1109/access.2018.2882240.
- S. V. Kolekar, R. M. Pai, M. P. MM, “Prediction of learner’s profile based on learning styles in adaptive e-learning system”, International Journal of Emerging Technologies in Learning, vol. 12, no. 6, 2017, doi:10.3991/ijet.v12i06.6579.
- M. M. Al-Tarabily, R. F. Abdel-Kader, G. Abdel Azeem, M. I. Marie, “Optimizing dynamic multi-agent performance in elearning environment”, IEEE Access, vol. 6, pp. 35631–35645, 2018, doi:10.1109/ACCESS.2018.2847334.
- Y. M. Tashtoush, M. Al-Soud, M. Fraihat,W. Al-Sarayrah, M. A. Alsmirat, “Adaptive e-learning web-based english tutor using data mining techniques and jackson’s learning styles”, “2017 8th International Conference on Information and Communication Systems (ICICS)”, pp. 86–91, 2017, doi:10.1109/IACS.2017.7921951.
- P. K. Udupi, N. Sharma, S. K. Jha, “Educational data mining and big data framework for e-learning environment”, “2016 5th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO)”, pp. 258–261, 2016, doi:10.1109/ICRITO.2016.7784961.
- K. Grigorova, E. Malysheva, S. Bobrovskiy, “Application of data mining and process mining approaches for improving e-learning processes”, pp. 1952–1958, Information technology and nanotechnology, 2017.
- B. Al Kurdi, M. Alshurideh, S. A. Salloum, “Investigating a theoretical framework for e-learning technology acceptance”, International Journal of Electrical and Computer Engineering (IJECE), vol. 10, no. 6, pp. 6484–6496, 2020, doi:10.11591/ijece.v10i6.pp6484-6496.
- F. Rasheed, A.Wahid, “Learning style detection in e-learning systems using machine learning techniques”, Expert Systems with Applications, vol. 174, p. 114774, 2021, doi:10.1016/j.eswa.2021.114774.
- M. El Mabrouk, S. Gaou, M. K. Rtili, “Towards an intelligent hybrid recommendation system for e-learning platforms using data mining”, International Journal of Emerging Technologies in Learning (Online), vol. 12, no. 6, p. 52, 2017, doi:10.3991/ijet.v12i06.6610.
- I. Bouchrika, N. Harrati, V. Wanick, G. Wills, “Exploring the impact of gamification on student engagement and involvement with
e-learning systems”, Interactive Learning Environments, vol. 29, no. 8, pp. 1244–1257, 2021, doi:10.1080/10494820.2019.1623267. - N. Harrati, I. Bouchrika, A. Tari, A. Ladjailia, “Exploring user satisfaction for e-learning systems via usage-based metrics and system usability scale analysis”, Computers in Human Behavior, vol. 61, pp. 463–471, 2016, doi:10.1016/j.chb.2016.03.051.
- J. Li, T. Tang, W. X. Zhao, J.-R. Wen, “Pretrained language models for text generation: A survey”, arXiv preprint arXiv:2105.10311, 2021.
- M. K. Afify, “E-learning content design standards based on interactive digital concepts maps in the light of meaningful and constructivist learning theory”, JOTSE: Journal of Technology and Science Education, vol. 8, no. 1, pp. 5–16, 2018.
- K. Premlatha, B. Dharani, T. Geetha, “Dynamic learner profiling and automatic learner classification for adaptive e-learning environment”, Interactive Learning Environments, vol. 24, no. 6, pp. 1054–1075, 2016, doi:10.1080/10494820.2014.948459.
- Y. A. Gomaa, R. AbuRaya, A. Omar, “The effects of information technology and e-learning systems on translation pedagogy and productivity of efl learners”, “2019 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT)”, pp. 1–6, 2019, doi:10.1109/3ICT.2019.8910326.
- E. Baralis, L. Cagliero, “Learning from summaries: Supporting elearning activities by means of document summarization”, IEEE
Transactions on Emerging Topics in Computing, vol. 4, no. 3, pp. 416–428,2016, doi:10.1109/TETC.2015.249333 - H. P. T. M. A. U. Gunathilaka, M. S. D. Fernando, “Individual learning path personalization approach in a virtual learning environment according to the dynamically changing learning styles and knowledge levels of the learner”, International Journal of ADVANCED AND APPLIED SCIENCES, vol. 5, no. 5, pp. 10–19, 2018, doi:10.21833/ijaas.2018.05.002.
- M. J. Hazar, M. Zrigui, M. Maraoui, “Learner comments-based recommendation system”, Procedia Computer Science, vol. 207, pp. 2000–2012, 2022, doi:10.1016/j.procs.2022.09.259.
- P. Okoro, “Upholding integrity in the management of e-learning in institutions of higher learning”, EPRA International Journal of Multidisciplinary Research (IJMR), vol. 8, no. 8, pp. 301–305, 2022,
doi:10.36713/epra11095. - G. A. A. J. Alkubaisi, N. S. Al-Saifi, A. R. Al-Shidi, “Recommended improvements for online learning platforms based on users’ experience in the sultanate of oman”, Higher Education, vol. 12, no. 3, 2022.
- A. Ouatiq, K. El-Guemmat, K. Mansouri, M. Qbadou, “A design of a multi-agent recommendation system using ontologies and rule-based reasoning: pandemic context”, International Journal of Electrical & Computer Engineering (2088-8708), vol. 12, no. 1, 2022, doi:10.11591/ijece.v12i1.pp515-523.
- P. K. Balasamy, K. Athiyappagounder, “An optimized feature selection method for e-learning recommender system using deep neural network based on multilayer perceptron”, International Journal of Intelligent Engineering and System, vol. 15, no. 5, p. 461, 2022.
- R. Marappan, S. Bhaskaran, “Analysis of recent trends in e-learning personalization techniques”, The Educational Review, USA, vol. 6, no. 5, pp. 167–170, 2022, doi:10.26855/er.2022.05.003.
- Z. Shahbazi, Y.-C. Byun, “Agent-based recommendation in elearning environment using knowledge discovery and machine learning approaches”, Mathematics, vol. 10, no. 7, p. 1192, 2022, doi:10.3390/math10071192.
- W. Bagunaid, N. Chilamkurti, P. Veeraraghavan, “Aisar: Artificial intelligence-based student assessment and recommendation system for e-learning in big data”, Sustainability, vol. 14, no. 17, p. 10551, 2022, doi:10.3390/su141710551.
- S. Reddy, I. Labutov, T. Joachims, “Latent skill embedding for personalized lesson sequence recommendation”, arXiv preprint arXiv:1602.07029, 2016.
- V. Gonzalez-Barbone, L. Anido-Rifon, “From scorm to common cartridge: A step forward”, Computers & Education, vol. 54, no. 1, pp. 88–102, 2010, doi:10.1016/j.compedu.2009.07.009.
- O. Bohl, J. Scheuhase, R. Sengler, U.Winand, “The sharable content object reference model (scorm) – a critical review”, “International Conference on Computers in Education, 2002. Proceedings.”, vol. 1 of CIE-02, p. 950–951, IEEE Comput. Soc, 2003, doi:10.1109/cie.2002.1186122.
- A. Kirkova-Bogdanova, “Standards in e-learning. scorm”, KNOWLEDGE-International Journal, vol. 47, no. 3, pp. 473–477, 2021.
- B. Furht, ed., Sharable Content Object Reference Model (SCORM), pp. 816–818, Springer US, Boston, MA, 2006, doi:10.1007/0-387-30038-4_225.
- G. Casella, G. Costagliola, F. Ferrucci, G. Polese, G. Scanniello, “A scorm thin client architecture for e-learning systems based on web services”, International Journal of Distance Education Technologies, vol. 5, no. 1, p. 19–36, 2007, doi:10.4018/jdet.2007010103.
- L. Argotte, G. Arroyo, J. Noguez, “Scorm sequencing and navigation model”, Research in Computing Science, vol. 65, no. 1, p. 111–119, 2013, doi:10.13053/rcs-65-1-10.
- D. Udugahapattuwa, M. Fernando, “A model for enhancing user experience in an e-learning system: A review on student behavior and content formatting”, “2023 7th SLAAI International Conference on Artificial Intelligence (SLAAI-ICAI)”, pp. 1–6, 2023, doi:10.1109/SLAAIICAI59257.2023.10365027.
- D. Udugahapattuwa, M. Fernando, “An intelligent model to enhance user experience in e-learning systems”, “2024 International Research Conference on Smart Computing and Systems Engineering (SCSE)”, vol. 7, pp. 1–6, 2024, doi:10.1109/SCSE61872.2024.10550860.
- D. Udugahapattuwa, M. Fernando, “An e-learning system model to enhance user experience with content recommendation”, “2024 Moratuwa Engineering Research Conference (MERCon)”, p. 1–6, IEEE, 2024, doi:10.1109/mercon63886.2024.10688835.